
Difference between revisions of "MOOC:Ressources"
From Livre IPv6
(→Structuration du prefixe global (GP)) |
(→Structuration du prefixe global (GP)) |
||
| Line 166: | Line 166: | ||
====Structuration du prefixe global (GP)==== | ====Structuration du prefixe global (GP)==== | ||
| − | |||
| − | {{HorsTexte|Comment obtenir un préfixe|Si vous êtes ISP en Europe pour obtenir un prefixe, vous pouvez vous | + | {{HorsTexte|Comment obtenir un préfixe|Si vous êtes ISP en Europe pour obtenir un prefixe, vous pouvez vous adresser au RIPE-NCC }} |
| + | |||
| + | A part le préfixe <tt>2002::</tt> qui est est réservé au mécanisme de transition [[6to4]], cet espace est géré hierarchiquement comme pour IPv4. L'IANA délègue aux 5 autorités régionales ([http://www.iana.org/numbers/ RIR]) des préfixes actuellement de longueur 12 (cf. http://www.iana.org/assignments/ipv6-unicast-address-assignments) qui les redistribuent aux ISP de leur region. | ||
====Structuration de l'identifiant de sous-réseau (SID)==== | ====Structuration de l'identifiant de sous-réseau (SID)==== | ||
Revision as of 21:16, 1 January 2009
Le format et la représentation des adresses sont les modifications les plus visibles pour l'utilisateur expérimenté et l'ingénieur réseau dans cette nouvelle version du protocole. En effet la taille de l'adresse reste fixe mais passe de 32 à 128 bits. Même si les principes sont fortement similaires à ceux employés dans IPv4, cet adressage apparaît à première vue beaucoup plus complexe. Il est intéressant d'en comprendre le principe et les règles d'attribution avant d'aborder les aspects protocolaires.
Ce chapitre passe en revue les différents types d'adresses. Il explique en détail le plan d'adressage agrégé qui a été retenu pour construire les réseaux de tests et opérationnels. Il décrit également la manière de calculer les identifiants d'interface utilisé par plusieurs types d'adresses (voir également Supports de transmission).
Contents
- 1 SpécificationsAspects fondamentaux de l'adressage IPv6
- 2 Mises en oeuvre
- 3 Questions ouvertes
- 4 Sujets de recherche
- 5 Références
- 6 Tutoriaux/Etudes de cas
- 7 Recherche
SpécificationsAspects fondamentaux de l'adressage IPv6
Représentation des adresses
La représentation textuelle d'une adresse IPv6 se fait en découpant le mot de 128 bits de l'adresse en 8 mots de 16 bits séparés par le caractère «:», chacun d'eux étant représenté en hexadécimal. Par exemple :
2001:0DB8:0000:0000:0400:A987:6543:210F
Dans un champ, il n'est pas nécessaire d'écrire les zéros placés en tête :
2001:DB8:0:0:400:A987:6543:210F
En outre plusieurs champs nuls consécutifs peuvent être abrégés par «::». Ainsi l'adresse précédente peut s'écrire comme suit :
2001:DB8::400:A987:6543:210F
Naturellement, pour éviter toute ambiguïté, l'abréviation «::» ne peut apparaître qu'une fois au plus dans une adresse. Les cas extrêmes sont l'adresse indéfinie (utilisée pour désigner les routes par défaut) à tous les bits à zéro et qui se note de manière compacte :
::
et l'adresse de bouclage (loopback), équivalent du préfixe 127/8 dont tous les bits sont à zéro sauf le dernier et qui s'écrit :
::1
La représentation des préfixes IPv6 est similaire à la notation CIDR RFC 1519 utilisée pour les préfixes IPv4. Un préfixe IPv6 est donc représenté par la notation :
adresse-ipv6/longueur-du-préfixe-en-bits
Les formes abrégées avec «::» sont autorisées.
2001:0DB8:7654:3210:0000:0000:0000:0000/64 2001:DB8:7654:3210:0:0:0:0/64 2001:DB8:7654:3210::/64
Le seul piège de cette notation vient des longueurs de préfixes qui ne sont pas en frontière de «:». Ainsi le préfixe 3EDC:BA98:7654:3::/56 équivaut en réalité à 3EDC:BA98:7654:0000::/56 car il s'écrit 3EDC:BA98:7654:0003::/56.
On peut combiner l'adresse d'une interface et la longueur du préfixe réseau associé en une seule notation.
2001:DB8:7654:3210:945:1321:ABA8:F4E2/64
Ces représentations peuvent apparaître beaucoup plus complexes qu'avec IPv4, mais leur attribution répond à des règles strictes, ce qui favorise leur mémorisation.
Dans certains cas, une adresse (voire plusieurs adresses) IPv4 peut être contenue dans une adresse IPv6. Pour les faire resortir, la notation classique d'IPv4 peut être utilisée au sein d'une adresse IPv6. Ainsi :
::128.12.13.14
représente une adresse IPv6 composée de 96 bits à 0 suivit des 32 bits de l'adresse IPv4 128.12.13.14
Il est pourtant parfois nécessaire de manipuler littéralement des adresses IPv6. Le caractère ":" utilisé pour séparer les mots peut créer des ambiguïtés. C'est le cas avec les URL où il est aussi utilisé pour indiquer le numéro de port. Ainsi l'URL
http://2001:DB8:12::1:8000/
peut aussi bien indiquer le port 8000 sur la machine ayant l'adresse IPv6 2001:DB8:12::1, que la machine 2001:DB8:12::1:8000 en utilisant le port par défaut. Pour lever cette ambiguïté, le RFC 2732 propose d'inclure l'adresse IPv6 entre "[ ]". L'adresse précédente s'écrirait :
http://[2001:DB8:12::1]:8000/
ou
http://[2001:DB8:12::1:8000]/
suivant les cas. Cette représentation peut être étendue à d'autres domaines comme X-window ou au protocole de signalisation téléphonique SIP.
Type des adresses
IPv6 reconnaît trois types d'adresses : unicast, multicast et anycast.
Le premier de ces types, le type unicast, est le plus simple. Une adresse de ce type désigne une interface unique. Un paquet envoyé à une telle adresse, sera donc remis à l'interface ainsi identifiée.
Parmi les adresses unicast, on peut distinguer celles qui auront une portée globale, c'est-à-dire désignant sans ambiguïté une machine sur le réseau Internet et celles qui auront une portée locale (lien ou site). Ces dernières ne pourront pas être routées sur l'Internet.
Une adresse de type multicast désigne un groupe d'interfaces qui en général appartiennent à des noeuds différents pouvant être situés n'importe où dans l'Internet. Lorsqu'un paquet a pour destination une adresse de type multicast, il est acheminé par le réseau à toutes les interfaces membres de ce groupe.
Il faut noter qu'il n'y a plus d'adresses de type broadcast comme sous IPv4 ; elles sont remplacées par des adresses de type multicast qui saturent moins un réseau local constitué de commutateurs. L'absence de broadcast augmente la résistance au facteur d'échelle d'IPv6 dans les réseaux commutés.
Le dernier type, anycast, est une officialisation de propositions faites pour IPv4 RFC 1546. Comme dans le cas du multicast, une adresse de type anycast désigne un groupe d'interfaces, la différence étant que lorsqu'un paquet a pour destination une telle adresse, il est acheminé à un des éléments du groupe et non pas à tous. C'est, par exemple, le plus proche au sens de la métrique des protocoles de routage. Cet adressage est principalement expérimental, voir Adresses anycast.
Certains types d'adresses sont caractérisés par leur préfixe RFC 3513. Le tableau suivant (source : http://www.iana.org/assignments/ipv6-address-space) donne la liste de ces préfixes. La plage «réservée» du préfixe 0::/8 est utilisée pour les adresses spéciales (adresse indéterminée, de bouclage, mappée, compatible). On notera que plus de 70% de l'espace disponible n'a pas été alloué, ce qui permet de conserver toute latitude pour l'avenir.
| Préfixe IPv6 | Allouer | Référence |
|---|---|---|
| 0000::/8 | Réservé pour la transition et loopback | RFC 3513 |
| 0100::/8 | Réservé | RFC 3513 |
| 0200::/7 | Réservé (ex NSAP) | RFC 4048 |
| 0400::/6 | Réservé (ex IPX) | RFC 3513 |
| 0800::/5 | Réservé | RFC 3513 |
| 1000::/4 | Réservé | RFC 3513 |
| 2000::/3 | Unicast Global | RFC 3513 |
| 4000::/3 | Réservé | RFC 3513 |
| 6000::/3 | Réservé | RFC 3513 |
| 8000::/3 | Réservé | RFC 3513 |
| A000::/3 | Réservé | RFC 3513 |
| C000::/3 | Réservé | RFC 3513 |
| E000::/4 | Réservé | RFC 3513 |
| F000::/5 | Réservé | RFC 3513 |
| F800::/6 | Réservé | RFC 3513 |
| FC00::/7 | Unique Local Unicast | RFC 4193 |
| FE00::/9 | Réservé | RFC 3513 |
| FE80::/10 | Lien-local | RFC 3513 |
| FEC0::/10 | Réservé | RFC 3879 |
| FF00::/8 | Multicast | RFC 3513 |
Dans un premier temps, des adresses du type site-local dans l'espace FEC0::/10 avaient été définies par l'IETF, mais elles ont été retirées dans les dernières versions des standards.
Une interface possèdera généralement plusieurs adresses IPv6. En IPv4 ce comportement est exceptionnel, il est banalisé en IPv6.
Adressage global : plan d'adressage agrégé
Ce plan, proposée dans le RFC 3587, précise la structure d'adressage IPv6 définie dans le RFC 3513 en précisant les tailles de chacun des blocs. Il est géré de la même manière que CIDR en IPv4. Une adresse intègre trois niveaux de hiérarchie :

Figure : Adresses Globales
- une topologie publique (appelée Global Prefix) codé sur 48 bits, allouée par le fournisseur d'accès;
- une topologie de site codé sur 16 bits (appelée Subnet ID). Ce champ permet de coder les numéros de sous réseau du site;
- un identifiant d'interface sur 64 bits (appelé Interface ID) distinguant les différentes machines sur le lien.
Structuration du prefixe global (GP)
Comment obtenir un préfixe
Si vous êtes ISP en Europe pour obtenir un prefixe, vous pouvez vous adresser au RIPE-NCC
A part le préfixe 2002:: qui est est réservé au mécanisme de transition 6to4, cet espace est géré hierarchiquement comme pour IPv4. L'IANA délègue aux 5 autorités régionales (RIR) des préfixes actuellement de longueur 12 (cf. http://www.iana.org/assignments/ipv6-unicast-address-assignments) qui les redistribuent aux ISP de leur region.
Structuration de l'identifiant de sous-réseau (SID)
Les clients reçoivent généralement un préfixe de longueur 48 de leur ISP.
En effet, si l'on garde l'attribution de préfixe de longueur 48 pour les sites terminaux, et que l'on intègre les réseaux domotiques, les opérateurs peuvent justifier d'un besoin important d'adresses que les autorités régionales ne peuvent leur refuser. Il semble que cela pourrait remettre en cause l'attribution de préfixes de longueur 48 pour tous les utilisateurs au profit de préfixes plus long.
Adressage local : adresses lien-local
Les adresses de type lien-local (link local use address) sont des adresses dont la validité est restreinte à un lien, c'est-à-dire l'ensemble de interfaces directement connectées sans routeur intermédiaire : par exemple machines branchées sur un même Ethernet, machines reliées par une connexion PPP, ou extrémités d'un tunnel. Les adresses lien-local sont configurées automatiquement à l'initialisation de l'interface et permettent la communication entre noeuds voisins. L'adresse est obtenue en concaténant le préfixe FE80::/64 aux 64 bits de l'identifiant d'interface.

Figure : Adresses Lien-local
Ces adresses sont utilisées par les protocoles de configuration d'adresse globale, de découverte de voisins (neighbor discovery) et de découverte de routeurs (router discovery). Ce sont de nouveaux dispositifs, le premier supplantant en particulier le protocole ARP (Address Resolution Protocol), qui permettent pas à un réseau local de se configurer automatiquement (voir Découverte de voisins). Elles sont également largement utilisées par les protocoles de routage soit pour l'échange de données (cf. RIPng, OSPFv3), soit dans les tables de routage puisque le champ prochain routeur est toujours un équipement directement accessible sur le lien.
Les adresses lien-local sont uniques à l'intérieur d'un lien. Le protocole de détection de duplication d'adresse (voir Détection d'adresse dupliquée) permet de s'en assurer. Par contre la duplication d'une adresse lien-local entre deux liens différents, ou entre deux interfaces d'un même noeud est autorisée.
Un routeur ne doit en aucun cas retransmettre un paquet ayant pour adresse source ou destination une adresse de type lien-local.
Le fait que ces adresses aient une portée très faible les limite dans la pratique au cas où un démarrage automatique (bootstrap) est nécessaire. Leur usage ne doit pas être généralisé dans les applications classiques en régime stabilisé.
Portée de l'adresse (scoped address)
Pour les adresses de type lien-local ou multicast qui ne permettent de désigner sans ambiguïté l'interface de sortie, il est nécessaire de la spécifier en ajoutant à la fin le nom de l'interface voulue, précédé du caractère "%".
Ainsi dans l'exemple suivant, issue d'une machine BSD :
>ping6 fe80::200:c0ff:fee4:caa0 PING6 fe80::1%lo0 --> fe80::200:c0ff:fee4:caa0 ping6: sendmsg: No route to host ping6: wrote fe80::200:c0ff:fee4:caa0 16 chars, ret=-1 ping6: sendmsg: No route to host ping6: wrote fe80::200:c0ff:fee4:caa0 16 chars, ret=-1 ^C --- fe80::200:c0ff:fee4:caa0 ping6 statistics --- 2 packets transmitted, 0 packets received, 100% packet loss
La station est incapable de déterminer l'interface de sortie, par contre si l'on utilise la même adresse de destination en précisant l'interface de sortie :
>ping6 fe80::200:c0ff:fee4:caa0%xl0 PING6 fe80::2b0:d0ff:fe3b:e565%xl0 --> fe80::200:c0ff:fee4:caa0%xl0 16 bytes from fe80::200:c0ff:fee4:caa0%xl0, icmp_seq=0 hlim=255 time=1 ms 16 bytes from fe80::200:c0ff:fee4:caa0%xl0, icmp_seq=1 hlim=255 time=1.067 ms ^C --- fe80::200:c0ff:fee4:caa0%xl0 ping6 statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 1/1.033/1.067 ms
on obtient le résultat attendu. La portée sera également utilisée avec les adresses multicast.
Choix de l'identifiants d'interface
EUI-64
L'IEEE a défini un identificateur global à 64 bits (format EUI-64) pour les réseaux IEEE 1394 qui vise une utilisation dans le domaine de la domotique. L'IEEE décrit les règles qui permettent de passer d'un identifiant MAC codé sur 48 bits à un EUI-64.
Il existe plusieurs méthodes pour construire l'identifiant :
- Si une machine ou une interface possède un identificateur global IEEE EUI-64, celui-ci a la structure décrite figure Identificateur global IEEE EUI-64.
Les 24 premiers bits de l'EUI-64, comme pour les adresses MAC IEEE 802, identifient le constructeur et les 40 autres bits identifient le numéro de série (les adresses MAC IEEE 802 n'en utilisaient que 24). Les 2 bits u (septième bit du premier octet) et g (huitième bit du premier octet) ont une signification spéciale :- u (Universel) vaut 0 si l'identifiant EUI-64 est universel,
- g (Groupe) indique si l'adresse est individuelle (g = 0), c'est-à-dire désigne un seul équipement sur le réseau, ou de groupe (g = 1), par exemple une adresse de multicast.
- L'ordre des bits ne doit pas porter à confusion. Dans la représentation numérique des valeurs, le premier bit transmis est le bit de poids faible, c'est-à-dire le bit de droite. Ainsi sur le support physique le bit g, puis le bit u puis les bits suivants sont transmis.
- L'identifiant d'interface à 64 bits est dérivé de l'EUI-64 en inversant le bit u (cf. figure Identificateur d'interface dérivé d'une EUI-64). En effet, pour la construction des adresses IPv6, on a préféré utiliser 1 pour marquer l'unicité mondiale. Cette inversion de la sémantique du bit permet de garder la valeur 0 pour une numérotation manuelle, autorisant à numéroter simplement les interfaces locales à partir de 1.

- Si une interface possède une adresse MAC IEEE 802 à 48 bits universelle (cas des interfaces Ethernet ou FDDI), cette adresse est utilisée pour construire des identifiants d'interface sur 64 bits, comme indiqué sur la figure ci-contre.
- A noter que l'IETF s'est trompée quand elle a défini l'algorithme de conversion. En effet, l'ajout de la valeur 0xFFFE concerne les EUI-48, c'est-à-dire des identifiants, alors qu'Ethernet utilise des MAC-48, c'est-à-dire des adresses (ils servent à transporter des trames vers le bon destinataire). La bonne valeur aurait été 0xFFFF. Mais cette erreur n'a aucune conséquence pour l'identification des équipements, elle n'a donc pas été corrigée par la suite.
- Si une interface possède une adresse locale unique sur le lien, mais non universelle (par exemple le format d'adresse IEEE 802 sur 2 octets ou une adresse sur un réseau Appletalk), l'identifiant d'interface est construit à partir de cette adresse en rajoutant des 0 en tête pour atteindre 64 bits.
- Si une interface ne possède aucune adresse (par exemple l'interface utilisée pour les liaisons PPP), et si la machine n'a pas d'identifiant EUI-64, il n'y a pas de méthode unique pour créer un identifiant d'interface. La méthode conseillée est d'utiliser l'identifiant d'une autre interface si c'est possible (cas d'une autre interface qui a une adresse MAC), ou une configuration manuelle ou bien une génération aléatoire, avec le bit u positionné à 0.
S'il y a conflit (les deux extrémités ont choisi la même valeur), il sera détecté lors de l'initialisation de l'adresse lien-local de l'interface, et devra être résolu manuellement.
Manuel
L'utilisation de l'adresse MAC pour construire l'adresse IP de la machine peut conduire dans certains cas à des problèmes de configuration, en particulier si la machine est un serveur. En effet, s'il l'on change la carte Ethernet de l'équipement (voire l'équipement) l'adresse IPv6 qui en dépend change également.
Le résolveur DNS est le cas le plus flagrant ; chaque machine sur le réseau doit être configurée avec l'adresse IPv6 du serveur DNS. En cas de changement de carte réseau, l'ensemble des machine du domaine devront être reconfigurées. Si l'on ne souhaite pas utiliser des protocoles de configuration automatique de type DHCPv6, il est préférable d'attribuer au résolveur DNS une adresse manuelle.
Valeur aléatoire
L'identifiant d'interface tel qu'il a été défini précédemment pourrait poser des problèmes pour la vie privée. Il identifie fortement la machine d'un utilisateur, qui même s'il se déplace de réseau en réseau garde ce même identifiant. Il serait alors possible de traquer un individu utilisant un portable, chez lui, au bureau, lors de ses déplacements. Ce problème est similaire à l'identificateur placé dans les processeurs Pentium III.
Pour couper court à toute menace de boycott d'un protocole qui «menacerait la vie privée», il a été proposé d'autres algorithmes de construction d'un identifiant d'interface basé sur des tirages aléatoires (voir RFC 3041). Un utilisateur particulièrement méfiant pourrait valider ces mécanismes. L'identifiant d'interface est soit choisi aléatoirement, soit construit par un algorithme comme MD5 à partir des valeurs précédentes, soit tiré au hasard si l'équipement ne peut pas mémoriser d'information entre deux démarrages. Périodiquement l'adresse est mise dans l'état «déprécié» et un nouvel identifiant d'interface est choisi. Les connexions déjà établies continuent d'utiliser l'ancienne valeur tandis que les nouvelles connexions utilisent la nouvelle adresse.
L'adresse publique globale est conservée, mais ne sera jamais choisie pour initier des communications. Elle permettra par contre d'en recevoir, même si l'anonymat est validé.
Bien entendu pour que ces mécanismes aient un sens, il faut que l'équipement ne s'enregistre pas sous un même nom dans un serveur DNS inverse ou que l'enregistrement de cookies dans un navigateur Web pour identifier l'utilisateur soit impossible.
Ces identifiants privés ne sont pas incompatibles avec les identifiants publics. Une machine peut attendre des ouvertures de connexions sur ses adresses publiques, par contre initier les connexions en utilisant ses identifiants privés. Il suffit de considérer que les adresses publiques sont dépréciées pour une durée indéterminée.

{kind=link}
{kind=link}
La figure Configuration des interfaces sous Windows illustre cette propriété, en retournant le résultat de la commande ipconfig. On peut noter que l'interface du réseau sans-fils possède trois adresses IPv6 (une lien locale et deux globales). Les adresses globales possèdent le même préfixe de 64 octets (2001:660:7307:6030::/64). La première adresse globale a le bit u=0 dans l'identifiant d'interface, il s'agit de celle générée aléatoirement. La deuxième à le bit u à 1 et l'on retrouve la séquence 0xFFFE au milieu de l'identifiant d'interface; cette adresse est dérivée de l'adresse MAC. Sous Windows, par défaut, les adresses aléatoires ont une durée de vie d'une semaine. Par exemple, en utilisant la commande netsh :
netsh interface ipv6>show address Recherche du statut actif... Interface 7 : Connexion réseau sans fil Type adr. État DAD Vie valide Vie préf. Adresse --------- --------- ---------- ---------- ----------------------------------- Temporaire Préféré 6d21h18m38s 21h15m51s 2001:660:7307:6030:c853:e48b:aafb:c354 Public Préféré 29d23h58m59s 6d23h58m59s 2001:660:7307:6030:204:e2ff:fe5a:9f Liaison Préféré infinite infinite fe80::204:e2ff:fe5a:9f
Cryptographique
Si un identifiant aléatoire permet de rendre beaucoup plus anonyme la source du paquet, des propositions sont faites à l'IETF pour lier l'identifiant d'interface à la clé publique de l'émetteur du paquet. Le RFC 3972 définit le principe de création de l'identifiant d'interface (CGA : Cryptographic Generated Addresses) à partir de la clé publique de la machine. Elles pourraient servir pour sécuriser les protocoles de découverte de voisins ou pour la gestion de la multi-domiciliation.
Mises en oeuvre
Questions ouvertes
Sujets de recherche
Références
Tutoriaux/Etudes de cas
Qu'est-ce qu'une adresse ?
La distinction entre les notions d'annuaires, de noms, d'adresses et de routes est comprise depuis longtemps. Cependant, depuis quelques années, au sein de l'Internet, la compréhension du rôle d'une adresse réseau a évolué. Dans l'Internet, une adresse sert en fait à deux fonctions distinctes : identification et localisation.
- L'identification est utilisée pendant une connexion par chacun des intervenants pour reconnaître son interlocuteur. Cela permet entre autres de s'assurer de l'origine des paquets reçus.
Cette vérification se fait dans les pseudo-en-têtes TCP ou dans les associations de sécurité d'IPsec. La durée de vie minimale d'un identificateur est celle d'une connexion TCP. - La localisation est utilisée pour trouver un intermédiaire qui saura délivrer les paquets. La durée de vie de la fonction de localisation est assez grande. En fait, elle ne varie qu'en cas de changement de prestataire IP ou de réorganisation du site.
En général la localisation est découpée en deux parties : localisation globale (identifiant le réseau) et locale, distinguant les machines sur un même réseau. La localisation est intrinsèquement liée aux fonctions de routage d'IP.
En IPv4, on confond identification et localisation en une seule entité, l'adresse IP, globalement unique dans l'Internet. Cette construction a un prix : lors de la renumérotation d'un site, ou lorsqu'un mobile se déplace, la localisation change. Avec l'approche IPv4, l'adresse IP change, et donc l'identification... Cela implique une perte ou au mieux une renégociation des communications en cours.
Lors des études initiales pour IPv6, il a été proposé de séparer ces deux fonctions pour pouvoir résoudre simplement les problèmes de renumérotation, mobilité, multi-domiciliation... Ceci est encore un sujet de recherche. Cette proposition n'a donc pas été retenue ; en IPv6 comme en IPv4, l'adresse sert à la fois pour l'identification et la localisation. En effet, le plan d'adressage choisi dans un premier temps est une extension des règles d'adressage hiérarchiques (CIDR) utilisées dans IPv4.
Un autre débat est de savoir si une adresse identifie une machine ou une interface. Cette distinction n'est pas très importante dans le cas d'une machine simple ne possédant qu'une seule interface ; elle le devient dans le cas où elle en possède plusieurs ou est multi-domiciliée. En effet pour essayer de simplifier les tables de routage dans le coeur de réseau, si un site est connecté à plusieurs fournisseur d'accès, il possédera autant de préfixes IPv6 que de fournisseurs. Contrairement à IPv4, où l'on associe généralement qu'une seule adresse à une interface, une interface possède plusieurs adresses IPv6.
Structuration des adresses et agrégation
Un des problèmes majeurs d'IPv4 est la croissance incontrôlée des tables de routage. Ce phénomène est dû à une mauvaise agrégation des adresses dans les tables. Il faudrait être capable de router des ensembles de réseaux identifiés par un seul descripteur. CIDR apporte une amélioration, mais celle-ci est insuffisante en pratique : les adresses IPv4 sont trop courtes pour permettre une bonne structuration, et il faut surtout assumer le coût du passé avec les adresses déjà allouées.
Attribuer une adresse à un équipement est un processus complexe, basé sur un compromis entre la facilité d'attribution et la facilité de gestion. Idéalement, pour minimiser la taille de routage, le réseau devrait avoir une topologie en arbre, cela rendrait l'adressage hiérarchique très efficace. Dans la réalité pour des raisons économiques, techniques, géographiques ou de performances, le réseau est beaucoup plus complexe et peut être vu comme un graphe. Il faut introduire des exceptions dans les tables de routages pour refléter cette topologie. On voit que pour avoir l'adressage le plus efficace possible, il faut dans ce graphe trouver la représentation arborescente qui génère le moins d'exceptions possibles. Or s'il était possible aujourd'hui de trouver une représentation valide, elle ne le sera pas nécessairement demain. En conséquence, la définition du plan d'adressage doit être la plus souple possible pour permettre une évolution de nature imprévisible.
D'autant plus que l'agrégation pour IPv4 ne semble plus aussi efficace. La figure suivante donne l'évolution de table de routage dans le coeur de l'Internet, c'est-à-dire dans les réseaux des opérateurs où aucune route par défaut n'est définie.

En 2000, la progression linéaire de cette table a semblé compromise du fait :
- de la baisse du coût des liaisons longues distances, permettant une multi-domiciliation (multi-homing) des sites pour des raisons de fiabilité (en cas de panne d'un opérateur, le trafic pourra passer par un autre), de performances (aller directement sur le réseau avec lequel le site à un trafic important),
- le manque d'adresses IPv4 qui force les opérateurs à allouer des préfixes de plus en plus long.
Depuis, les opérateurs ont fortement aggrégé pour revenir à une progression linéaire de la table. Des études [BTC02] montrent que :
- la multi-domiciliation, c'est-à-dire la connexion d'un site à plusieurs opérateurs pour fiabiliser l'accès, ajoute un surcoût de 20 à 30 pourcent,
- le partage de charge, c'est-à-dire réduire l'agregation pour annoncer un sous-ensemble de préfixe à chaque opérateur, induit un surcoût de 20 à 25 pourcent,
- de mauvaises règles d'agrégation induisent une surcharge de 15 à 20 pourcent,
- la fragmentation de l'espace d'adressage liée à la gestion des préfixes avant CIDR, et à l'allocation séquencielle des blocks d'adresses contribue à plus de 75 pourcent de la taille de la table.
Actuellement, pour pouvoir assurer une bonne agrégation, les règles utilisées par CIDR pour IPv4 sont conservées. Mais la gestion des tables de routage dans le coeur du réseau s'en trouvera quand même améliorée car :
- dès le début le plan d'adressage est hiérarchique, éliminant les longs préfixes,
- les sites multi-domiciliés posséderont autant d'adresses que de fournisseurs, permettant ainsi de garantir une agrégation.
- des mécanismes de renumérotation automatiques permettent aux sites de changer facilement de préfixe quand cela est nécessaire.
Si un plan d'adressage hiérarchique semble actuellement le plus adapté, d'autres règles de numérotation pourraient être utilisées dans le futur, comme par exemple, les coordonnées géographiques de l'équipement. Ces techniques ne sont actuellement utilisées que dans quelques laboratoires de recherche pour des réseaux ad hoc, mais il reste assez de place dans l'espace d'adressage pour prendre en compte ces nouveaux types de réseaux si un jour ils se généralisent.
Le choix d'un plan d'adressage a fait l'objet de nombreux débats à l'IETF. Il a été beaucoup plus difficile à définir que le format du paquet IPv6 présenté au chapitre suivant. Plusieurs plans ont été proposés puis abandonnés. Ces divers plans d'adressages sont commentés dans le chapitre sur l'Historique de la standardisation d'IPv6. Le présent chapitre se contente de décrire les différents plans d'adressage actuellement utilisés.
Durée de vie des adresses
IPv6 généralisant le plan d'adressage CIDR, les préfixes restent dans tous les cas la propriété des opérateurs. Il ne peuvent plus être attribués "à vie" aux équipements. Pour faciliter la renumérotation d'une machine l'attribution d'une adresse à une interface est faite temporairement, les adresses IPv6 ne sont pas données mais prêtées. Une durée de vie est associée à l'adresse qui indique le temps pendant lequel l'adresse appartient à l'interface. Quand la durée de vie est épuisée, l'adresse devient invalide, elle est supprimée de l'interface et devient potentiellement assignable à une autre interface. Une adresse invalide ne doit jamais être utilisée comme adresse dans des communications. La valeur par défaut de la durée de vie d'une adresse est de 30 jours, mais cette durée peut être prolongée, ou portée à l'infini. L'adresse lien-local a une durée de vie illimitée.
La renumérotation d'une interface d'une machine consiste à passer d'une adresse à une autre. Lors d'une renumérotation, il n'est pas souhaitable de changer brusquement d'adresse, sinon toutes les communications TCP, qui l'utilisent comme identificateur de connexion, seraient immédiatement coupées. Ceci entraînerait des perturbations importantes au niveau des applications.
Pour faciliter cette transition, un mécanisme d'obsolescence est donc mis en place pour invalider progressivement une adresse. Ce mécanisme s'appuie sur la capacité d'affectation de plusieurs adresses valides à une même interface. Ensuite pour effectuer le choix de l'adresse à utiliser, un état est associé. Il indique dans quelle phase de sa durée de vie une adresse se situent vis à vis de l'interface. Le premier de ces états est qualifié de préféré : l'utilisation n'est aucunement restreinte. Peu avant son invalidation l'adresse passe dans un état de déprécié. Dans cet état, l'utilisation de l'adresse est déconseillée, mais pas interdite. L'adresse dépréciée ne doit plus être utilisée comme adresse de source pour les nouvelles communications (comme l'établissement de connexion TCP). Par contre l'adresse dépréciée peut encore servir d'adresse de source dans le cas des communications existantes. Les paquets reçus à une adresse dépréciée continuent à être remis normalement. À la durée de vie de validité d'un adresse, il est également associé une durée de vie pour son état préféré. La figure 3-2 représente les différents états que prend une adresse lorsqu'elle est allouée à une interface.

Notation
Adresses de test
Les expérimentations d'IPv6 sur un réseau devaient commencer avant que les règles d'attribution des préfixes soient complètement finalisées. La valeur 0x1FFE a été attribué par l'IANA au 6bone dans le plan d'adressage agrégé pour les expérimentations (RFC 3701). Il correspond au préfixe 3FFE::/16 pour l'ensemble du 6bone.
{kind=link}
Les 48 bits restant avant le champ Subnet ID recréent les niveaux hiérarchiques d'un réseau IPv6 défini dans le RFC 3587, d'où le terme pseudo accolé au nom du champ. La taille réduite n'étant pas un facteur limitant dans la phase expérimentale. Des pseudo-TLA d'une taille initialement de 8, mais portées à 12 bits par la suite, sont attribués à des opérateurs voulant expérimenter le protocole. Les 24 ou 20 bits suivants sont utilisés pour numéroter les sites.
Les pseudo-TLA ont été alloués jusqu'en décembre 2003 aux opérateurs qui en faisaient la demande. La liste complète est disponible sur le serveur Web http://www.6bone.net/6bone_pTLA_list.html. Le tableau Pseudo TLA attribués par le groupe ngtrans reprend quelques unes de ces valeurs.
| Organismes/Pays | Préfixe | Organismes/Pays | Préfixe | |
|---|---|---|---|---|
| ROOT66/US-CA | 3FFE:0000::/24 | TRUMPET/AU | 3FFE:8000::/28 | |
| TELEBIT/DK | 3FFE:0100::/24 | ICM-PL/PL | 3FFE:8010::/28 | |
| SICS/SE | 3FFE:0200::/24 | IIJ/JP | 3FFE:8020::/28 | |
| G6/FR | 3FFE:0300::/24 | QTPVSIX/EU | 3FFE:8030::/28 | |
| JOIN/DE | 3FFE:0400::/24 | APAN-KR | 3FFE:8040::/28 | |
| WIDE/JP | 3FFE:0500::/24 | MIBH | 3FFE:8050::/28 | |
| SURFNET/NL | 3FFE:0600::/24 | ATNET-AT | 3FFE:8060::/28 |
L'expérimentation lié au 6bone s'est terminée récemment; la date d'arrêt a été symboliquement choisie le mardi 6 juin 2006 RFC 3701. En effet, si ce réseau a servi palier à l'absence d'opérateurs officiels au début de l'introduction d'IPv6, il a vite montré ses limites. L'utilisation de tunnels pour créer la connectivité a conduit à un trop fort maillage, à des routes relativement longues et par conséquence à une faible qualité de service.
Adresses gérées par les RIR
La valeur 0x0001 a été attribué par l'IANA pour un plan d'adressage où les autorités régionales attribuent les préfixes. Le préfixe initial est par conséquent 2001::/16. Ce plan reproduit, en étendant la largeur des champs les principes de délégation et de gestion introduits en IPv4 par CIDR. Un site voulant se connecter reçoit de son fournisseur d'accès un préfixe global de longueur supérieure ou égale à 48 bits.
Les adresses de type lien-local (link local use address) sont des adresses dont la validité est restreinte à un lien, c'est-à-dire l'ensemble de interfaces directement connectées sans routeur intermédiaire : par exemple machines branchées sur un même Ethernet, machines reliées par une connexion PPP, ou extrémités d'un tunnel. Les adresses lien-local sont configurées automatiquement à l'initialisation de l'interface et permettent la communication entre noeuds voisins. L'adresse est obtenue en concaténant le préfixe FE80::/64 aux 64 bits de l'identifiant d'interface.
{kind=link}
Ces adresses sont utilisées par les protocoles de configuration d'adresse globale, de découverte de voisins (neighbor discovery) et de découverte de routeurs (router discovery). Ce sont de nouveaux dispositifs, le premier supplantant en particulier le protocole ARP (Address Resolution Protocol), qui permettent pas à un réseau local de se configurer automatiquement (voir Découverte de voisins).
Les adresses lien-local sont uniques à l'intérieur d'un lien. Le protocole de détection de duplication d'adresse (voir Détection d'adresse dupliquée) permet de s'en assurer. Par contre la duplication d'une adresse lien-local entre deux liens différents, ou entre deux interfaces d'un même noeud est autorisée.
Un routeur ne doit en aucun cas retransmettre un paquet ayant pour adresse source ou destination une adresse de type lien-local.
Le fait que ces adresses aient une portée très faible les limite dans la pratique au cas où un démarrage automatique (bootstrap) est nécessaire. Leur usage ne doit pas être généralisé dans les applications classiques en régime stabilisé.
Selection du type d'identifiant d'interface
Si l'on sélectionne correctement le type d'identifiant d'interface, la gestion de l'adressage IPv6 est aussi facile (voire plus simple) qu'en IPv6. Ainsi, il est préférable de donner aux serveurs des identifiants d'inteface construit manuellement. Il sera ainsi beaucoup plus facile de se rappeler de leur adresse. De plus si l'équipement est remplacé et par conséquent que la carte réseau est différente, l'adresse IPv6 restera stable. Pour les clients, il est plus simple d'utiliser l'identifiant d'interface construit à partir de l'adresse MAC.
Les adresses site-local sont des adresses dont la validité était restreinte à un site. Par exemple, un site qui n'est pas encore connecté à l'Internet pouvait utiliser ces adresses, ce qui le dispensait de demander ou d'emprunter un préfixe. Ce système généralisait le concept d'adresse privée d'IPv4 (comme le réseau 10.x.y.z). Un autre intérêt apparent des adresses site-local est qu'elles ne sont pas modifiées lors d'un changement de fournisseur de connectivité, qui ne perturbe donc pas les communications locales.
Une adresse site-local était construite en concaténant le préfixe FEC0::/48, un champ de 16 bits qui permet de définir plusieurs sous-réseaux, et les 64 bits de l'identifiant d'interface.
{kind=link}
Malgré ces propriétés, les adresses site-local n'ont pas réussi à s'imposer durant la phase de standardisation d'IPv6. Suivant les règles de l'IETF, elle doivent donc être retirées des documents pour la version finale du RFC décrivant IPv6. Le RFC 3879 décrit les problèmes liés à l'utilisation des adresses site-local. Contrairement à un lien facilement délimité par le support physique, la frontière du site est beaucoup plus vague. Il s'en suit des ambiguïtés qui rendent difficile l'utilisation de ce concept. En particulier, si un utilisateur est connecté à deux sites de deux companies différentes, l'adressage à plat offert par les adresses site-local rendent le routage difficile. Si le site dispose aussi d'adresses globales, l'ajout systématique d'adresses site-local rend également plus difficile le choix des adresses source et destination ainsi que la réponse aux requêtes DNS qui dépendent de la position de l'équipement demandeur.
De plus si le réseau de deux companies fusionnent, comme l'adressage des sous-réseaux ne se fait que dans la partie Subnet ID, il y a de fortes chances de trouver des collisions dans les valeurs choisies.
Unique Local Address
Les adresses de type site-local étant supprimées du standard IPv6 [RFC 3879], le RFC 4193 définit un nouveau format d'adresse unicast : les adresses uniques locales (ULA : Unique Local Address). Ces adresses sont destinées à une utilisation locale. Elles ne sont pas définies pour être routées dans l'Internet, mais seulement au sein d'une zone limitée telle qu'un site ou entre un nombre limité de sites. Les adresses uniques locales ont les caractéristiques suivantes :
- Prefixe globalement unique.
- Préfixe clairement définit facilitant le filtrage sur les routeurs de bordure.
- Permet l'interconnexion de sites sans générer de conflit d'adresse et sans nécessiter de renumérotation.
- Indépendantes des fournisseurs d'accès à l'Internet et ne nécessitent donc pas de connectivité.
- Pas de conflit en cas de routage par erreur en dehors d'un site.
- Aucune différences pour les applications, qui peuvent les considérer comme des adresses globales unicast standard.
Les adresses uniques locales sont créées en utilisant un identifiant global (Global ID) généré pseudo-aléatoirement. Ces adresses suivent le format suivant :
- Prefix (7 bits) : FC00::/7 préfixe identifiant les adresses IPv6 locales (ULA)
- L (1 bit) : Positionné à 1, le préfixe est assigné localement. La valeur 0 est réservée pour une utilisation future.
- Global ID (40 bits) : Identifiant global utilisé pour la création d'un préfixe unique (Globally Unique Prefix).
- Subnet ID (16 bits) : Identifiant d'un sous réseau à l'intérieur du site.
- Interface ID (64 bits) : L'indentifiant d'interface tel que définit dans Identifiant d'interface.
Les adresses site-local sont des adresses dont la validité était restreinte à un site. Par exemple, un site qui n'est pas encore connecté à l'Internet pouvait utiliser ces adresses, ce qui le dispensait de demander ou d'emprunter un préfixe. Ce système généralisait le concept d'adresse privée d'IPv4 (comme le réseau 10.x.y.z). Un autre intérêt apparent des adresses site-local est qu'elles ne sont pas modifiées lors d'un changement de fournisseur de connectivité, qui ne perturbe donc pas les communications locales.
Une adresse site-local était construite en concaténant le préfixe FEC0::/48, un champ de 16 bits qui permet de définir plusieurs sous-réseaux, et les 64 bits de l'identifiant d'interface.
Malgré ces propriétés, les adresses site-local n'ont pas réussi à s'imposer durant la phase de standardisation d'IPv6. Suivant les règles de l'IETF, elle doivent donc être retirées des documents pour la version finale du RFC décrivant IPv6. Le RFC 3879 décrit les problèmes liés à l'utilisation des adresses site-local. Contrairement à un lien facilement délimité par le support physique, la frontière du site est beaucoup plus vague. Il s'en suit des ambiguïtés qui rendent difficile l'utilisation de ce concept. En particulier, si un utilisateur est connecté à deux sites de deux companies différentes, l'adressage à plat offert par les adresses site-local rendent le routage difficile. Si le site dispose aussi d'adresses globales, l'ajout systématique d'adresses site-local rend également plus difficile le choix des adresses source et destination ainsi que la réponse aux requêtes DNS qui dépendent de la position de l'équipement demandeur.
De plus si le réseau de deux companies fusionnent, comme l'adressage des sous-réseaux ne se fait que dans la partie Subnet ID, il y a de fortes chances de trouver des collisions dans les valeurs choisies.
Unique Local Address
Les adresses de type site-local étant supprimées du standard IPv6 [RFC 3879], le RFC 4193 définit un nouveau format d'adresse unicast : les adresses uniques locales (ULA : Unique Local Address). Ces adresses sont destinées à une utilisation locale. Elles ne sont pas définies pour être routées dans l'Internet, mais seulement au sein d'une zone limitée telle qu'un site ou entre un nombre limité de sites. Les adresses uniques locales ont les caractéristiques suivantes :
- Prefixe globalement unique.
- Préfixe clairement définit facilitant le filtrage sur les routeurs de bordure.
- Permet l'interconnexion de sites sans générer de conflit d'adresse et sans nécessiter de renumérotation.
- Indépendantes des fournisseurs d'accès à l'Internet et ne nécessitent donc pas de connectivité.
- Pas de conflit en cas de routage par erreur en dehors d'un site.
- Aucune différences pour les applications, qui peuvent les considérer comme des adresses globales unicast standard.
Les adresses uniques locales sont créées en utilisant un identifiant global (Global ID) généré pseudo-aléatoirement. Ces adresses suivent le format suivant :
- Prefix (7 bits) : FC00::/7 préfixe identifiant les adresses IPv6 locales (ULA)
- L (1 bit) : Positionné à 1, le préfixe est assigné localement. La valeur 0 est réservée pour une utilisation future.
- Global ID (40 bits) : Identifiant global utilisé pour la création d'un préfixe unique (Globally Unique Prefix).
- Subnet ID (16 bits) : Identifiant d'un sous réseau à l'intérieur du site.
- Interface ID (64 bits) : L'indentifiant d'interface tel que définit dans Identifiant d'interface.
Le listing suivant donne la configuration des interfaces d'une machine sous Unix.
>ifconfig -au
vr0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet 192.108.119.159 netmask 0xffffff80 broadcast 192.108.119.255
inet6 fe80::250:baff:febe:712%vr0 prefixlen 64 scopeid 0x1
inet6 2001:660:7301:1:250:baff:febe:712 prefixlen 64 autoconf
inet6 2001:688:1f99:1:250:baff:febe:712 prefixlen 64 autoconf
ether 00:50:ba:be:07:12
media: Ethernet autoselect (10baseT/UTP)
status: active
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384
inet 127.0.0.1 netmask 0xff000000
inet6 ::1 prefixlen 128
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x3
L'interface Ethernet vr0 possède une adresse IPv4 et trois adresses IPv6 :
- La première adresse correspond à l'adresse lien-local. On retrouve l'identifiant d'interface qui suit le préfixe FE80::/64. A noter que l'on retrouve les octets de l'adresse MAC, sauf pour le premier octet qui est à 02 au lieu de 00 suite à l'inversion du bit «universel/local».
A noter que la portée de l'adresse est indiquée par la chaîne de caractère %vr0. La valeur scopeid indiquée à la fin de la ligne donne le numéro cette interface.
- Les deux autres adresses correspondent à des adresses globales dont les préfixes ont éte attribués par deux opérateurs différents (la machine est sur un réseau multi-domicilié) :
- 2001 : une adresse unicast globale attribuée par les autorités régionales (cf. Familles d'adressage),
- 660 : est le préfixe attibué par RIPE-NCC au réseau Renater et 688 à France Télécom
- 7301 est attribué par Renater à l'ENST-Bretagne et 1f99 par France Télécom,
- 1 : est le numéro du réseau, pour ces deux préfixes, à l'intérieur de l'ENST Bretagne. Il n'est pas nécessaire d'attribuer le même identifiant de sous-réseaux pour les deux préfixes, mais cela est préférable pour des raisons de commodité d'administration.
L'interface de lo0 possède les adresses de loopback pour IPv4 et IPv6 (::1).
Le principe sous-jacent est simple : au lieu d'envoyer un paquet à une interface déterminée, on envoie ce paquet à une adresse (anycast) qui représente un ensemble de machines dans un domaine bien défini. Une adresse anycast permet de désigner un service par une adresse bien connue, de cette manière, il n'est pas nécessaire d'interroger un serveur pour connaître la localisation d'un équipement.
La figure Adresse anycast «sous-réseau» donne la structure de l'adresse anycast. On y retrouve une partie préfixe et une partie identifiant anycast. La partie préfixe est la même que celle utilisée pour les adresses unicast. Contrairement aux structures d'adresses vue précédemment, la longueur de ce préfixe n'est pas spécifiée, car une adresse anycast doit s'adapter aussi bien aux plans d'adressage actuels (où la longueur est généralement de 64 bits) qu'aux futurs plans qui pourraient avoir des tailles différentes.
Si le concept anycast est simple dans son principe, son implémentation est autrement délicate. En outre, ce concept n'est encore qu'un sujet de recherche. Enfin un autre argument, de taille, explique cette prudence : il n'y a eu aucune expérience grandeur nature analogue au projet Mbone pour le multicast.
Comme les adresses de type sont allouées dans le même espace d'adressage, elles sont créées en attribuant une même adresse unicast à des noeuds distincts, chacun des noeuds devant être configuré pour que l'adresse ainsi attribuée soit de type anycast (sinon on aurait une adresse unicast dupliquée). La seule manière de différencier une adresse anycast d'une adresse multicast est de regarder la partie identifiant anycast qui diffère d'un identifiant d'interface. Ainsi la séquence binaire composée uniquement de 0 a été la première valeur retenue. Elle permet d'identifier un des routeurs du lien. Le RFC 2526 définit des règles de construction d'autres identifiants anycast sur un lien en réservant les 128 identifiants d'interface locaux les plus élevés. Cela permet d'éviter les conflits avec une numérotation manuelle qui partent des identifiants les plus petits vers les plus élevés. Le tableau Allocation des identifiants Anycast donne l'allocation des identifiants utilisés.
Allocation des identifiants Anycast
Description
Valeur(hexadécimal)
Réservé
0x7F
Adresse Anycast de l'agent mère (cf.Mobilité dans IPv6)
0x7E
Réservé
0x00 à 0x7D
Deux modes de fonctionnement non exclusifs sont possibles. Le premier consiste à attribuer sur un préfixe déjà utilisé la même adresse anycast à plusieurs équipements. Le seconde consiste à définir des adresses sur un préfixe "virtuel" et à router au plus près. Les paragraphes suivants expliquent ces modes de fonctionnement.
Adresses anycast sur un même lien
Avec les adresses anycast, plusieurs équipements sur un lien physique possèdent une même adresse IPv6. Or il ne s'agit pas d'envoyer la même information à tous ces équipements comme en multicast, mais d'en choisir un seul. Une possibilité consiste à utiliser le mécanisme de découverte de voisins (cf. Découverte de voisins) pour trouver l'association entre l'adresse IPv6 et l'adresse MAC.
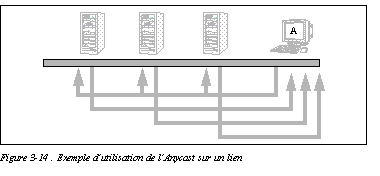
La figure Exemple d'utilisation de l'Anycast sur un lien illustre ce fonctionnement. La station A envoie un message de sollicitation de voisin pour déterminer l'adresse MAC de l'équipement. Trois serveurs reçoivent cette requête et répondent. La station A prendra une de ces réponses et dialoguera en point-à-point avec l'équipement choisi.
Préfixe virtuel
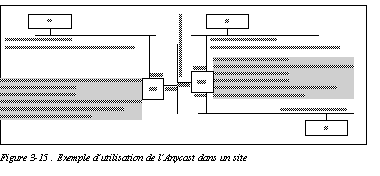
Une adresse anycast peut être aussi construite à partir d'un préfixe "virtuel", c'est-à-dire appartenant au site (ou même à un domaine plus grand), mais non alloué à un lien particulier. Le schéma Exemple d'utilisation de l'Anycast dans un site donne un exemple de cette configuration. Les routeurs contiennent des adresses dans les tables de routage (c'est-à-dire des préfixes de longueur 128) pour router vers l'équipement le plus proche. Le sous-réseau 7 a été réservé aux adresses anycast. Les réseaux de 1 à 4 correspondent à des liens. Quand la station C émet un paquet Anycast vers l'adresse 2001:...:7:FFFF:FFFF:FFFF:FF7D, le routeur R2 route le paquet vers les sous-réseau 1.
Recherche
Les adresses de type site-local étant supprimées du standard IPv6 [RFC 3879], le RFC 4193 définit un nouveau format d'adresse unicast : les adresses uniques locales (ULA : Unique Local Address). Ces adresses sont destinées à une utilisation locale. Elles ne sont pas définies pour être routées dans l'Internet, mais seulement au sein d'une zone limitée telle qu'un site ou entre un nombre limité de sites. Les adresses uniques locales ont les caractéristiques suivantes :
- Prefixe globalement unique.
- Préfixe clairement définit facilitant le filtrage sur les routeurs de bordure.
- Permet l'interconnexion de sites sans générer de conflit d'adresse et sans nécessiter de renumérotation.
- Indépendantes des fournisseurs d'accès à l'Internet et ne nécessitent donc pas de connectivité.
- Pas de conflit en cas de routage par erreur en dehors d'un site.
- Aucune différences pour les applications, qui peuvent les considérer comme des adresses globales unicast standard.
Les adresses uniques locales sont créées en utilisant un identifiant global (Global ID) généré pseudo-aléatoirement. Ces adresses suivent le format suivant :
- Prefix (7 bits) : FC00::/7 préfixe identifiant les adresses IPv6 locales (ULA)
- L (1 bit) : Positionné à 1, le préfixe est assigné localement. La valeur 0 est réservée pour une utilisation future.
- Global ID (40 bits) : Identifiant global utilisé pour la création d'un préfixe unique (Globally Unique Prefix).
- Subnet ID (16 bits) : Identifiant d'un sous réseau à l'intérieur du site.
- Interface ID (64 bits) : L'indentifiant d'interface tel que définit dans Identifiant d'interface.
Les adresses site-local sont des adresses dont la validité était restreinte à un site. Par exemple, un site qui n'est pas encore connecté à l'Internet pouvait utiliser ces adresses, ce qui le dispensait de demander ou d'emprunter un préfixe. Ce système généralisait le concept d'adresse privée d'IPv4 (comme le réseau 10.x.y.z). Un autre intérêt apparent des adresses site-local est qu'elles ne sont pas modifiées lors d'un changement de fournisseur de connectivité, qui ne perturbe donc pas les communications locales.
Une adresse site-local était construite en concaténant le préfixe FEC0::/48, un champ de 16 bits qui permet de définir plusieurs sous-réseaux, et les 64 bits de l'identifiant d'interface.
Malgré ces propriétés, les adresses site-local n'ont pas réussi à s'imposer durant la phase de standardisation d'IPv6. Suivant les règles de l'IETF, elle doivent donc être retirées des documents pour la version finale du RFC décrivant IPv6. Le RFC 3879 décrit les problèmes liés à l'utilisation des adresses site-local. Contrairement à un lien facilement délimité par le support physique, la frontière du site est beaucoup plus vague. Il s'en suit des ambiguïtés qui rendent difficile l'utilisation de ce concept. En particulier, si un utilisateur est connecté à deux sites de deux companies différentes, l'adressage à plat offert par les adresses site-local rendent le routage difficile. Si le site dispose aussi d'adresses globales, l'ajout systématique d'adresses site-local rend également plus difficile le choix des adresses source et destination ainsi que la réponse aux requêtes DNS qui dépendent de la position de l'équipement demandeur.
De plus si le réseau de deux companies fusionnent, comme l'adressage des sous-réseaux ne se fait que dans la partie Subnet ID, il y a de fortes chances de trouver des collisions dans les valeurs choisies.
Unique Local Address
Les adresses de type site-local étant supprimées du standard IPv6 [RFC 3879], le RFC 4193 définit un nouveau format d'adresse unicast : les adresses uniques locales (ULA : Unique Local Address). Ces adresses sont destinées à une utilisation locale. Elles ne sont pas définies pour être routées dans l'Internet, mais seulement au sein d'une zone limitée telle qu'un site ou entre un nombre limité de sites. Les adresses uniques locales ont les caractéristiques suivantes :
- Prefixe globalement unique.
- Préfixe clairement définit facilitant le filtrage sur les routeurs de bordure.
- Permet l'interconnexion de sites sans générer de conflit d'adresse et sans nécessiter de renumérotation.
- Indépendantes des fournisseurs d'accès à l'Internet et ne nécessitent donc pas de connectivité.
- Pas de conflit en cas de routage par erreur en dehors d'un site.
- Aucune différences pour les applications, qui peuvent les considérer comme des adresses globales unicast standard.
Les adresses uniques locales sont créées en utilisant un identifiant global (Global ID) généré pseudo-aléatoirement. Ces adresses suivent le format suivant :
- Prefix (7 bits) : FC00::/7 préfixe identifiant les adresses IPv6 locales (ULA)
- L (1 bit) : Positionné à 1, le préfixe est assigné localement. La valeur 0 est réservée pour une utilisation future.
- Global ID (40 bits) : Identifiant global utilisé pour la création d'un préfixe unique (Globally Unique Prefix).
- Subnet ID (16 bits) : Identifiant d'un sous réseau à l'intérieur du site.
- Interface ID (64 bits) : L'indentifiant d'interface tel que définit dans Identifiant d'interface.
Le listing suivant donne la configuration des interfaces d'une machine sous Unix.
>ifconfig -au
vr0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet 192.108.119.159 netmask 0xffffff80 broadcast 192.108.119.255
inet6 fe80::250:baff:febe:712%vr0 prefixlen 64 scopeid 0x1
inet6 2001:660:7301:1:250:baff:febe:712 prefixlen 64 autoconf
inet6 2001:688:1f99:1:250:baff:febe:712 prefixlen 64 autoconf
ether 00:50:ba:be:07:12
media: Ethernet autoselect (10baseT/UTP)
status: active
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384
inet 127.0.0.1 netmask 0xff000000
inet6 ::1 prefixlen 128
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x3
L'interface Ethernet vr0 possède une adresse IPv4 et trois adresses IPv6 :
- La première adresse correspond à l'adresse lien-local. On retrouve l'identifiant d'interface qui suit le préfixe FE80::/64. A noter que l'on retrouve les octets de l'adresse MAC, sauf pour le premier octet qui est à 02 au lieu de 00 suite à l'inversion du bit «universel/local».
A noter que la portée de l'adresse est indiquée par la chaîne de caractère %vr0. La valeur scopeid indiquée à la fin de la ligne donne le numéro cette interface.
- Les deux autres adresses correspondent à des adresses globales dont les préfixes ont éte attribués par deux opérateurs différents (la machine est sur un réseau multi-domicilié) :
- 2001 : une adresse unicast globale attribuée par les autorités régionales (cf. Familles d'adressage),
- 660 : est le préfixe attibué par RIPE-NCC au réseau Renater et 688 à France Télécom
- 7301 est attribué par Renater à l'ENST-Bretagne et 1f99 par France Télécom,
- 1 : est le numéro du réseau, pour ces deux préfixes, à l'intérieur de l'ENST Bretagne. Il n'est pas nécessaire d'attribuer le même identifiant de sous-réseaux pour les deux préfixes, mais cela est préférable pour des raisons de commodité d'administration.
L'interface de lo0 possède les adresses de loopback pour IPv4 et IPv6 (::1).
Le principe sous-jacent est simple : au lieu d'envoyer un paquet à une interface déterminée, on envoie ce paquet à une adresse (anycast) qui représente un ensemble de machines dans un domaine bien défini. Une adresse anycast permet de désigner un service par une adresse bien connue, de cette manière, il n'est pas nécessaire d'interroger un serveur pour connaître la localisation d'un équipement.
La figure Adresse anycast «sous-réseau» donne la structure de l'adresse anycast. On y retrouve une partie préfixe et une partie identifiant anycast. La partie préfixe est la même que celle utilisée pour les adresses unicast. Contrairement aux structures d'adresses vue précédemment, la longueur de ce préfixe n'est pas spécifiée, car une adresse anycast doit s'adapter aussi bien aux plans d'adressage actuels (où la longueur est généralement de 64 bits) qu'aux futurs plans qui pourraient avoir des tailles différentes.
Si le concept anycast est simple dans son principe, son implémentation est autrement délicate. En outre, ce concept n'est encore qu'un sujet de recherche. Enfin un autre argument, de taille, explique cette prudence : il n'y a eu aucune expérience grandeur nature analogue au projet Mbone pour le multicast.
Comme les adresses de type sont allouées dans le même espace d'adressage, elles sont créées en attribuant une même adresse unicast à des noeuds distincts, chacun des noeuds devant être configuré pour que l'adresse ainsi attribuée soit de type anycast (sinon on aurait une adresse unicast dupliquée). La seule manière de différencier une adresse anycast d'une adresse multicast est de regarder la partie identifiant anycast qui diffère d'un identifiant d'interface. Ainsi la séquence binaire composée uniquement de 0 a été la première valeur retenue. Elle permet d'identifier un des routeurs du lien. Le RFC 2526 définit des règles de construction d'autres identifiants anycast sur un lien en réservant les 128 identifiants d'interface locaux les plus élevés. Cela permet d'éviter les conflits avec une numérotation manuelle qui partent des identifiants les plus petits vers les plus élevés. Le tableau Allocation des identifiants Anycast donne l'allocation des identifiants utilisés.
Allocation des identifiants Anycast
Description
Valeur(hexadécimal)
Réservé
0x7F
Adresse Anycast de l'agent mère (cf.Mobilité dans IPv6)
0x7E
Réservé
0x00 à 0x7D
Deux modes de fonctionnement non exclusifs sont possibles. Le premier consiste à attribuer sur un préfixe déjà utilisé la même adresse anycast à plusieurs équipements. Le seconde consiste à définir des adresses sur un préfixe "virtuel" et à router au plus près. Les paragraphes suivants expliquent ces modes de fonctionnement.
Adresses anycast sur un même lien
Avec les adresses anycast, plusieurs équipements sur un lien physique possèdent une même adresse IPv6. Or il ne s'agit pas d'envoyer la même information à tous ces équipements comme en multicast, mais d'en choisir un seul. Une possibilité consiste à utiliser le mécanisme de découverte de voisins (cf. Découverte de voisins) pour trouver l'association entre l'adresse IPv6 et l'adresse MAC.
La figure Exemple d'utilisation de l'Anycast sur un lien illustre ce fonctionnement. La station A envoie un message de sollicitation de voisin pour déterminer l'adresse MAC de l'équipement. Trois serveurs reçoivent cette requête et répondent. La station A prendra une de ces réponses et dialoguera en point-à-point avec l'équipement choisi.
Préfixe virtuel
Une adresse anycast peut être aussi construite à partir d'un préfixe "virtuel", c'est-à-dire appartenant au site (ou même à un domaine plus grand), mais non alloué à un lien particulier. Le schéma Exemple d'utilisation de l'Anycast dans un site donne un exemple de cette configuration. Les routeurs contiennent des adresses dans les tables de routage (c'est-à-dire des préfixes de longueur 128) pour router vers l'équipement le plus proche. Le sous-réseau 7 a été réservé aux adresses anycast. Les réseaux de 1 à 4 correspondent à des liens. Quand la station C émet un paquet Anycast vers l'adresse 2001:...:7:FFFF:FFFF:FFFF:FF7D, le routeur R2 route le paquet vers les sous-réseau 1.
Recherche
Les adresses de type site-local étant supprimées du standard IPv6 [RFC 3879], le RFC 4193 définit un nouveau format d'adresse unicast : les adresses uniques locales (ULA : Unique Local Address). Ces adresses sont destinées à une utilisation locale. Elles ne sont pas définies pour être routées dans l'Internet, mais seulement au sein d'une zone limitée telle qu'un site ou entre un nombre limité de sites. Les adresses uniques locales ont les caractéristiques suivantes :
- Prefixe globalement unique.
- Préfixe clairement définit facilitant le filtrage sur les routeurs de bordure.
- Permet l'interconnexion de sites sans générer de conflit d'adresse et sans nécessiter de renumérotation.
- Indépendantes des fournisseurs d'accès à l'Internet et ne nécessitent donc pas de connectivité.
- Pas de conflit en cas de routage par erreur en dehors d'un site.
- Aucune différences pour les applications, qui peuvent les considérer comme des adresses globales unicast standard.
Les adresses uniques locales sont créées en utilisant un identifiant global (Global ID) généré pseudo-aléatoirement. Ces adresses suivent le format suivant :
- Prefix (7 bits) : FC00::/7 préfixe identifiant les adresses IPv6 locales (ULA)
- L (1 bit) : Positionné à 1, le préfixe est assigné localement. La valeur 0 est réservée pour une utilisation future.
- Global ID (40 bits) : Identifiant global utilisé pour la création d'un préfixe unique (Globally Unique Prefix).
- Subnet ID (16 bits) : Identifiant d'un sous réseau à l'intérieur du site.
- Interface ID (64 bits) : L'indentifiant d'interface tel que définit dans Identifiant d'interface.
Le listing suivant donne la configuration des interfaces d'une machine sous Unix.
>ifconfig -au vr0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500 inet 192.108.119.159 netmask 0xffffff80 broadcast 192.108.119.255 inet6 fe80::250:baff:febe:712%vr0 prefixlen 64 scopeid 0x1 inet6 2001:660:7301:1:250:baff:febe:712 prefixlen 64 autoconf inet6 2001:688:1f99:1:250:baff:febe:712 prefixlen 64 autoconf ether 00:50:ba:be:07:12 media: Ethernet autoselect (10baseT/UTP) status: active lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384 inet 127.0.0.1 netmask 0xff000000 inet6 ::1 prefixlen 128 inet6 fe80::1%lo0 prefixlen 64 scopeid 0x3
L'interface Ethernet vr0 possède une adresse IPv4 et trois adresses IPv6 :
- La première adresse correspond à l'adresse lien-local. On retrouve l'identifiant d'interface qui suit le préfixe FE80::/64. A noter que l'on retrouve les octets de l'adresse MAC, sauf pour le premier octet qui est à 02 au lieu de 00 suite à l'inversion du bit «universel/local».
A noter que la portée de l'adresse est indiquée par la chaîne de caractère %vr0. La valeur scopeid indiquée à la fin de la ligne donne le numéro cette interface. - Les deux autres adresses correspondent à des adresses globales dont les préfixes ont éte attribués par deux opérateurs différents (la machine est sur un réseau multi-domicilié) :
- 2001 : une adresse unicast globale attribuée par les autorités régionales (cf. Familles d'adressage),
- 660 : est le préfixe attibué par RIPE-NCC au réseau Renater et 688 à France Télécom
- 7301 est attribué par Renater à l'ENST-Bretagne et 1f99 par France Télécom,
- 1 : est le numéro du réseau, pour ces deux préfixes, à l'intérieur de l'ENST Bretagne. Il n'est pas nécessaire d'attribuer le même identifiant de sous-réseaux pour les deux préfixes, mais cela est préférable pour des raisons de commodité d'administration.
L'interface de lo0 possède les adresses de loopback pour IPv4 et IPv6 (::1).
Le principe sous-jacent est simple : au lieu d'envoyer un paquet à une interface déterminée, on envoie ce paquet à une adresse (anycast) qui représente un ensemble de machines dans un domaine bien défini. Une adresse anycast permet de désigner un service par une adresse bien connue, de cette manière, il n'est pas nécessaire d'interroger un serveur pour connaître la localisation d'un équipement.
{kind=link}
La figure Adresse anycast «sous-réseau» donne la structure de l'adresse anycast. On y retrouve une partie préfixe et une partie identifiant anycast. La partie préfixe est la même que celle utilisée pour les adresses unicast. Contrairement aux structures d'adresses vue précédemment, la longueur de ce préfixe n'est pas spécifiée, car une adresse anycast doit s'adapter aussi bien aux plans d'adressage actuels (où la longueur est généralement de 64 bits) qu'aux futurs plans qui pourraient avoir des tailles différentes.
Si le concept anycast est simple dans son principe, son implémentation est autrement délicate. En outre, ce concept n'est encore qu'un sujet de recherche. Enfin un autre argument, de taille, explique cette prudence : il n'y a eu aucune expérience grandeur nature analogue au projet Mbone pour le multicast.
Comme les adresses de type sont allouées dans le même espace d'adressage, elles sont créées en attribuant une même adresse unicast à des noeuds distincts, chacun des noeuds devant être configuré pour que l'adresse ainsi attribuée soit de type anycast (sinon on aurait une adresse unicast dupliquée). La seule manière de différencier une adresse anycast d'une adresse multicast est de regarder la partie identifiant anycast qui diffère d'un identifiant d'interface. Ainsi la séquence binaire composée uniquement de 0 a été la première valeur retenue. Elle permet d'identifier un des routeurs du lien. Le RFC 2526 définit des règles de construction d'autres identifiants anycast sur un lien en réservant les 128 identifiants d'interface locaux les plus élevés. Cela permet d'éviter les conflits avec une numérotation manuelle qui partent des identifiants les plus petits vers les plus élevés. Le tableau Allocation des identifiants Anycast donne l'allocation des identifiants utilisés.
| Description | Valeur(hexadécimal) |
|---|---|
| Réservé | 0x7F |
| Adresse Anycast de l'agent mère (cf.Mobilité dans IPv6) | 0x7E |
| Réservé | 0x00 à 0x7D |
Deux modes de fonctionnement non exclusifs sont possibles. Le premier consiste à attribuer sur un préfixe déjà utilisé la même adresse anycast à plusieurs équipements. Le seconde consiste à définir des adresses sur un préfixe "virtuel" et à router au plus près. Les paragraphes suivants expliquent ces modes de fonctionnement.
Adresses anycast sur un même lien
Avec les adresses anycast, plusieurs équipements sur un lien physique possèdent une même adresse IPv6. Or il ne s'agit pas d'envoyer la même information à tous ces équipements comme en multicast, mais d'en choisir un seul. Une possibilité consiste à utiliser le mécanisme de découverte de voisins (cf. Découverte de voisins) pour trouver l'association entre l'adresse IPv6 et l'adresse MAC.
La figure Exemple d'utilisation de l'Anycast sur un lien illustre ce fonctionnement. La station A envoie un message de sollicitation de voisin pour déterminer l'adresse MAC de l'équipement. Trois serveurs reçoivent cette requête et répondent. La station A prendra une de ces réponses et dialoguera en point-à-point avec l'équipement choisi.

Préfixe virtuel
Une adresse anycast peut être aussi construite à partir d'un préfixe "virtuel", c'est-à-dire appartenant au site (ou même à un domaine plus grand), mais non alloué à un lien particulier. Le schéma Exemple d'utilisation de l'Anycast dans un site donne un exemple de cette configuration. Les routeurs contiennent des adresses dans les tables de routage (c'est-à-dire des préfixes de longueur 128) pour router vers l'équipement le plus proche. Le sous-réseau 7 a été réservé aux adresses anycast. Les réseaux de 1 à 4 correspondent à des liens. Quand la station C émet un paquet Anycast vers l'adresse 2001:...:7:FFFF:FFFF:FFFF:FF7D, le routeur R2 route le paquet vers les sous-réseau 1.
