
Difference between revisions of "Les extensions"
From Livre IPv6
(→<div id=PeP> Proche-en-proche </div>) |
(→<div id="frag">Fragmentation </div>) |
||
| Line 93: | Line 93: | ||
La fragmentation telle qu'elle est pratiquée dans IPv4 n'est pas très performante. Initialement, elle servait à rendre transparente les limitations physiques des supports de transmission. Dans IPv4 quand un routeur ne peut pas transmettre un paquet à cause de sa trop grande taille et si le bit <tt>DF</tt> (''don't fragment'') est à 0, il découpe l'information à transmettre en fragments. Or le réseau IP étant un réseau à datagramme, il n'y a pas de possibilité de contrôler les fragments. Deux fragments successifs peuvent prendre deux chemins différents et par conséquent seul le destinataire peut effectuer le réassemblage. En conséquence, après la traversée d'un lien impliquant une fragmentation, le reste du réseau ne voit passer que des paquets de taille réduite. | La fragmentation telle qu'elle est pratiquée dans IPv4 n'est pas très performante. Initialement, elle servait à rendre transparente les limitations physiques des supports de transmission. Dans IPv4 quand un routeur ne peut pas transmettre un paquet à cause de sa trop grande taille et si le bit <tt>DF</tt> (''don't fragment'') est à 0, il découpe l'information à transmettre en fragments. Or le réseau IP étant un réseau à datagramme, il n'y a pas de possibilité de contrôler les fragments. Deux fragments successifs peuvent prendre deux chemins différents et par conséquent seul le destinataire peut effectuer le réassemblage. En conséquence, après la traversée d'un lien impliquant une fragmentation, le reste du réseau ne voit passer que des paquets de taille réduite. | ||
| − | Il est plus intéressant d'adapter la taille des paquets à l'émission. Ceci est fait en utilisant les techniques de découverte du MTU (voir [[ | + | Il est plus intéressant d'adapter la taille des paquets à l'émission. Ceci est fait en utilisant les techniques de découverte du MTU (voir [[Mécanisme de découverte de PMTU]] (RFC 1981)). En pratique une taille de paquets de 1 500 octets est presque universelle. |
Il existe pourtant des cas où la fragmentation est nécessaire. Ainsi une application telle que NFS sur UDP suppose que la fragmentation existe et produit des messages de grande taille. Comme on ne veut pas modifier ces applications, la couche réseau d'IPv6 doit aussi être capable de gérer la fragmentation. Pour réduire le travail des routeurs intermédiaires, la fragmentation se fera chez l'émetteur et le réassemblage chez le récepteur. | Il existe pourtant des cas où la fragmentation est nécessaire. Ainsi une application telle que NFS sur UDP suppose que la fragmentation existe et produit des messages de grande taille. Comme on ne veut pas modifier ces applications, la couche réseau d'IPv6 doit aussi être capable de gérer la fragmentation. Pour réduire le travail des routeurs intermédiaires, la fragmentation se fera chez l'émetteur et le réassemblage chez le récepteur. | ||
Revision as of 07:11, 20 November 2005
Les extensions d'IPv6 peuvent être vues comme un prolongement de l'encapsulation d'IP dans IP. À part l'extension de proche-en-proche traitée par tous les routeurs intermédiaires, les autres extensions ne sont prises en compte que par les équipements destinataires du paquet.
Une extension a une longueur multiple de 8 octets. Elle commence par un champ en-tête suivant d'un octet qui définit le type de données qui suit l'extension : une autre extension ou un protocole de niveau 4 (voir tableau Valeurs du champ en-tête suivant). Pour les extensions à longueur variable, l'octet suivant contient la longueur de l'extension en mots de 8 octets, le premier n'étant pas compté (une extension de 16 octets a un champ longueur de 1).
| valeur | Extension | valeur | Protocole | ||
|---|---|---|---|---|---|
| 0 | proche-en-proche | 4 | IPv4 | ||
| 43 | Routage | 6 | TCP | ||
| 44 | Fragmentation | 17 | UDP | ||
| 50 | [[#conf | Confidentialité]] | 41 | IPv6 | |
| 51 | [[#auth | Authentification]] | 58 | ICMPv6 | |
| 59 | Fin des en-têtes | 132 | SCTP | ||
| 60 | Destination | 135 | Binding Update (mobilité) | ||
| 136 | UDP-lite |
Le RFC 2460 recommande l'ordre suivant :
- Proche-en-proche (doit toujours être en première position)
- Destination (sera aussi traité par les routeurs listés dans l'extension de routage par la source)
- Routage par la source
- Fragmentation
- Authentification
- Destination (traité uniquement par l'équipement terminal)
Proche-en-proche
Cette extension (en anglais : hop-by-hop) se situe toujours en première position et est traitée par tous les routeurs que le paquet traverse. Le type associé (contenu dans le champ d'en-tête en-tête suivant de l'en-tête précédent) est 0 et le champ longueur de l'extension contient le nombre de mots de 64 bits moins 1.
L'extension est composée d'options. Pour l'instant, seules quatre options, dont deux de bourrage, sont définies (cf. format Format des options IPv6). Chaque option est une suite d'octets. Le premier octet est un type, le deuxième (sauf pour l'option 0) contient la longueur de l'option moins 2. Les deux premiers bits de poids fort du type définissent le comportement du routeur quand il rencontre une option inconnue :

- 00 : le routeur ignore l'option ;
- 01 : le routeur rejette le paquet ;
- 10 : le routeur rejette le paquet et retourne un message ICMPv6 d'inaccessibilité ;
- 11 : le routeur rejette le paquet et retourne un message ICMPv6 d'inaccessibilité si l'adresse de destination n'est pas multicast.
Le bit suivant du type indique que le routeur peut modifier le contenu du champ option (valeur à 1) ou non (valeur à 0).

Les quatre options de proche-en-proche sont :
- Pad1 (type 0). Cette option est utilisée pour introduire un octet de bourrage.
- Padn (type 1). Cette option est utilisée pour introduire plus de 2 octets de bourrage. Le champ longueur indique le nombre d'octets qui suivent.
Les options de bourrage peuvent sembler inutiles avec IPv6 puisqu'un champ longueur pourrait en donner la longueur exacte. En fait les options de bourrage servent à optimiser le traitement des paquets en alignant les champs sur des mots de 32, voire 64 bits ; le RFC 2460 discute en annexe de la manière d'optimiser le traitement tout en minimisant la place prise par les options.
- Jumbogramme (type 194 ou 0xc2, RFC 2675). Cette option est utilisée quand le champ longueur des données du paquet IPv6 n'est pas suffisant pour coder la taille du paquet. Cette option est essentiellement prévue pour la transmission à grand débit entre deux équipements. Si l'option jumbogramme est utilisée, le champ longueur des données utiles dans l'en-tête IPv6 vaut 0.
Noter que le type commence par la séquence binaire 11, ce qui permet au routeur ne traitant pas les jumbogrammes d'en informer la source. Celle-ci pourra réémettre l'information sans utiliser cette option.
- L'option Router Alert (RFC 2675) demande à un routeur d'examiner le contenu des données qu'il relaie (Router Alert existe également en IPv4, RFC 2113). En principe, le processus de relayage (recopier le paquet sur une interface de sortie en fonction de l'adresse destination et des tables de routage) doit être le plus rapide possible. Mais pour des protocoles comme la gestion des groupes de multicast avec MLD (Multicast Listener Discovery) ou la signalisation des flux avec RSVP, tous les routeurs intermédiaires doivent tenir compte des données.
L'émetteur envoie les données à la destination, mais s'il précise l'option Router Alert, les routeurs intermédiaires vont analyser les données, voire modifier leur contenu avant de relayer le paquet. Ce mécanisme est efficace puisque les routeurs n'ont pas à analyser le contenu de tous les paquets d'un flux.
Le type de l'option vaut 5. Il commence par la séquence binaire 00, puisqu'un routeur qui ne connaît pas cette option doit relayer le paquet sans le modifier. Le champ valeur de l'option contient :- 0 : pour les messages du protocole MLD de gestion des groupes multicast ;
- 1 : pour les messages RSVP ;
- 2 : pour les réseaux actifs ;
- les autres valeurs sont réservées.
Destination
Cette extension, dont le format est identique à l'extension de proche-en-proche (cf. figure Format des extensions "proche-en-proche" et "destination"), contient des options qui sont traitées par l'équipement destinataire. Pour l'instant, à part les options de bourrage (voir Pad1 et Padn) et de mobilité (cf. Mobilité dans IPv6), la seule autre option concerne le tunnelage dans des paquets IPv6 (RFC 2473). Cette option permet de limiter le niveau d'encapsulation dans des tunnels des paquets IPv6.
Routage
Cette extension permet d'imposer à un paquet une route différente de celle offerte par les politiques de routage présentes sur le réseau. Pour l'instant seul le routage par la source (type = 0), similaire à l'option Loose Source Routing d'IPv4, est défini.
Dans IPv4, le routage peut être strict (le routeur suivant présent dans la liste doit être un voisin directement accessible) ou libéral (loose) (un routeur peut utiliser les tables de routage pour joindre le routeur suivant servant de relais). Dans IPv6, seul le routage libéral est autorisé. En effet, le routage strict était initialement mis en place surtout pour des raisons de sécurité. La source devait être absolument sûre du chemin pris par les paquets. Cette utilisation a maintenant disparu du réseau.
Le principe du routage par la source ou Source Routing dans IPv4 est rappelé en introduction de ce chapitre sur les extensions. Le principe est le même pour IPv6. L'émetteur met dans le champ destination du paquet IPv6, l'adresse du premier routeur servant de relais, l'extension contient la suite de la liste des autres routeurs relais et le destinataire. Quand un routeur reçoit un paquet qui lui est adressé comportant une extension de routage par la source, il permute son adresse avec l'adresse du prochain routeur et réémet le paquet vers cette adresse suivante.
La figure Format de l'extension routage par la source donne le format de l'extension de routage par la source :
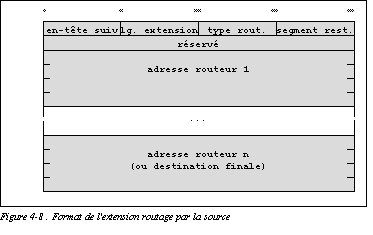
- Le champ longueur de l'en-tête indique le nombre de mots de 64 bits qui composent l'extension. Pour l'extension de type 0, cela correspond au nombre d'adresses présentes dans la liste, multiplié par 2.
- Le champ type indique la nature du routage. Pour l'instant, seul le routage par la source, de type 0 est spécifié. La suite de l'en-tête correspond à ce type.
- Le nombre de segments restant est décrémenté après la traversée d'un routeur. Il indique le nombre d'équipements qui doivent encore être traversés. Il permet de trouver l'adresse qui devra être substituée.
- Les 32 bits suivants sont inutilisés pour préserver l'alignement.
La liste comprenant les routeurs à traverser et le destinataire est fournie. Ces adresses ne peuvent pas être multicast.
Fragmentation
La fragmentation telle qu'elle est pratiquée dans IPv4 n'est pas très performante. Initialement, elle servait à rendre transparente les limitations physiques des supports de transmission. Dans IPv4 quand un routeur ne peut pas transmettre un paquet à cause de sa trop grande taille et si le bit DF (don't fragment) est à 0, il découpe l'information à transmettre en fragments. Or le réseau IP étant un réseau à datagramme, il n'y a pas de possibilité de contrôler les fragments. Deux fragments successifs peuvent prendre deux chemins différents et par conséquent seul le destinataire peut effectuer le réassemblage. En conséquence, après la traversée d'un lien impliquant une fragmentation, le reste du réseau ne voit passer que des paquets de taille réduite.
Il est plus intéressant d'adapter la taille des paquets à l'émission. Ceci est fait en utilisant les techniques de découverte du MTU (voir Mécanisme de découverte de PMTU (RFC 1981)). En pratique une taille de paquets de 1 500 octets est presque universelle.
Il existe pourtant des cas où la fragmentation est nécessaire. Ainsi une application telle que NFS sur UDP suppose que la fragmentation existe et produit des messages de grande taille. Comme on ne veut pas modifier ces applications, la couche réseau d'IPv6 doit aussi être capable de gérer la fragmentation. Pour réduire le travail des routeurs intermédiaires, la fragmentation se fera chez l'émetteur et le réassemblage chez le récepteur.
Le format de l'extension de fragmentation est donné See Format de l'extension de fragmentation.La signification des champs est identique à celle d'IPv4 :

Le champ place du fragment indique lors du réassemblage où les données doivent être insérées. Ceci permet de parer les problèmes dus au déséquencement dans les réseaux orientés datagrammes. Comme ce champ est sur 13 bits, la taille de tous les segments, sauf du dernier, doit être multiple de 8 octets.
Le bit M s'il vaut 1 indique qu'il y aura d'autres fragments émis.
Le champ identification permet de repérer les fragments appartenant à un même paquet initial. Il est différent pour chaque paquet et recopié dans ses fragments.
Le bit DF (don't fragment) n'est plus nécessaire puisque, si un paquet est trop grand, il y aura rejet du paquet par le routeur.
Dans IPv4, la valeur d'une option était codée de manière à indiquer au routeur effectuant la fragmentation si elle devait être copiée dans les fragments. Dans IPv6, l'en-tête et les extensions qui concernent les routeurs intermédiaires (pour l'instant proche-en-proche, routage par la source) sont recopiées dans chaque fragment.
Sécurité
Deux extensions de sécurité -- les extensions d'authentification AH (Authentication Header) et de confidentialité ESP (Encapsulating Security Payload) -- sont définies par l'IETF. Elles permettent de protéger les communications passées sur les réseaux IPv6 mais aussi IPv4 en assurant les services de confidentialité, authentification, intégrité et détection de rejeux. Le chapite Sécurité, RFC 2402 donne une description détaillée de ces extensions, et présente les modes de protection existants.
Suite : Exemples d'extensions
Cette extension permet d'imposer à un paquet une route différente de celle offerte par les politiques de routage présentes sur le réseau. Pour l'instant seul le routage par la source (type = 0), similaire à l'option Loose Source Routing d'IPv4, est défini.
Dans IPv4, le routage peut être strict (le routeur suivant présent dans la liste doit être un voisin directement accessible) ou libéral (loose) (un routeur peut utiliser les tables de routage pour joindre le routeur suivant servant de relais). Dans IPv6, seul le routage libéral est autorisé. En effet, le routage strict était initialement mis en place surtout pour des raisons de sécurité. La source devait être absolument sûre du chemin pris par les paquets. Cette utilisation a maintenant disparu du réseau.
Le principe du routage par la source ou Source Routing dans IPv4 est rappelé en introduction de ce chapitre sur les extensions. Le principe est le même pour IPv6. L'émetteur met dans le champ destination du paquet IPv6, l'adresse du premier routeur servant de relais, l'extension contient la suite de la liste des autres routeurs relais et le destinataire. Quand un routeur reçoit un paquet qui lui est adressé comportant une extension de routage par la source, il permute son adresse avec l'adresse du prochain routeur et réémet le paquet vers cette adresse suivante.
La figure Format de l'extension routage par la source donne le format de l'extension de routage par la source :

- Le champ longueur de l'en-tête indique le nombre de mots de 64 bits qui composent l'extension. Pour l'extension de type 0, cela correspond au nombre d'adresses présentes dans la liste, multiplié par 2.
- Le champ type indique la nature du routage. Pour l'instant, seul le routage par la source, de type 0 est spécifié. La suite de l'en-tête correspond à ce type.
- Le nombre de segments restant est décrémenté après la traversée d'un routeur. Il indique le nombre d'équipements qui doivent encore être traversés. Il permet de trouver l'adresse qui devra être substituée.
- Les 32 bits suivants sont inutilisés pour préserver l'alignement.
La liste comprenant les routeurs à traverser et le destinataire est fournie. Ces adresses ne peuvent pas être multicast.
Fragmentation
La fragmentation telle qu'elle est pratiquée dans IPv4 n'est pas très performante. Initialement, elle servait à rendre transparente les limitations physiques des supports de transmission. Dans IPv4 quand un routeur ne peut pas transmettre un paquet à cause de sa trop grande taille et si le bit DF (don't fragment) est à 0, il découpe l'information à transmettre en fragments. Or le réseau IP étant un réseau à datagramme, il n'y a pas de possibilité de contrôler les fragments. Deux fragments successifs peuvent prendre deux chemins différents et par conséquent seul le destinataire peut effectuer le réassemblage. En conséquence, après la traversée d'un lien impliquant une fragmentation, le reste du réseau ne voit passer que des paquets de taille réduite.
Il est plus intéressant d'adapter la taille des paquets à l'émission. Ceci est fait en utilisant les techniques de découverte du MTU (voir Mécanisme de découverte de PMTU (RFC 1981)). En pratique une taille de paquets de 1 500 octets est presque universelle.
Il existe pourtant des cas où la fragmentation est nécessaire. Ainsi une application telle que NFS sur UDP suppose que la fragmentation existe et produit des messages de grande taille. Comme on ne veut pas modifier ces applications, la couche réseau d'IPv6 doit aussi être capable de gérer la fragmentation. Pour réduire le travail des routeurs intermédiaires, la fragmentation se fera chez l'émetteur et le réassemblage chez le récepteur.
Le format de l'extension de fragmentation est donné See Format de l'extension de fragmentation.La signification des champs est identique à celle d'IPv4 :

Le champ place du fragment indique lors du réassemblage où les données doivent être insérées. Ceci permet de parer les problèmes dus au déséquencement dans les réseaux orientés datagrammes. Comme ce champ est sur 13 bits, la taille de tous les segments, sauf du dernier, doit être multiple de 8 octets.
Le bit M s'il vaut 1 indique qu'il y aura d'autres fragments émis.
Le champ identification permet de repérer les fragments appartenant à un même paquet initial. Il est différent pour chaque paquet et recopié dans ses fragments.
Le bit DF (don't fragment) n'est plus nécessaire puisque, si un paquet est trop grand, il y aura rejet du paquet par le routeur.
Dans IPv4, la valeur d'une option était codée de manière à indiquer au routeur effectuant la fragmentation si elle devait être copiée dans les fragments. Dans IPv6, l'en-tête et les extensions qui concernent les routeurs intermédiaires (pour l'instant proche-en-proche, routage par la source) sont recopiées dans chaque fragment.
Sécurité
Deux extensions de sécurité -- les extensions d'authentification AH (Authentication Header) et de confidentialité ESP (Encapsulating Security Payload) -- sont définies par l'IETF. Elles permettent de protéger les communications passées sur les réseaux IPv6 mais aussi IPv4 en assurant les services de confidentialité, authentification, intégrité et détection de rejeux. Le chapite Sécurité, RFC 2402 donne une description détaillée de ces extensions, et présente les modes de protection existants.
Suite : Exemples d'extensions