
Direccionamiento
From Livre IPv6
| |
Introducción | Table des matières | Planes de direccionamiento | |
Direccionamiento
El formato y la representación de las direcciones son las modificaciones más visibles para el usuario experimentado y el ingeniero de la red en esta nueva versión del protocolo. Aunque los principios son muy similares a los utilizados en IPv4, el nuevo direccionamiento parece mucho más complejo. Resulta interesante conocer los principios y las reglas de atribución antes de entrar en los detalles del protocolo.
Una dirección IPv6 es una palabra de 128 bits. El tamaño de una dirección IPv6 es cuatro veces mayor que la de una dirección IPv4. Teniendo en cuenta las estimaciones más pesimistas y las más optimistas [BM95], se obtiene el siguiente cuadro, en el cual la unidad es el número de direcciones por metro cuadrado de superficie de la tierra (incluyendo océanos):
<math>1,564 < Direcciones\_disponibles < 3,911,873,538,269,506,102</math>
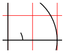
Figure :
Otros cálculos indican que se podrían destinar 60,000 millones de billones de direcciones por habitante.
Por supuesto, estos cálculos son completamente arbitrarios. Es difícil predecir el uso de direcciones en los próximos años. Por ejemplo, el esquema de direccionamiento actualmente implementado, utiliza 64 bits para el identificador de dispositivos, es decir, la mitad del tamaño de la dirección.
En realidad, este tipo de cálculo sirve de justificación para los partidarios de las direcciones de tamaño fijo (lo que simplifica el procesamiento de paquetes) pues muestran que el número de dispositivos direccionables es realmente enorme.
Sin embargo, no hay que perder el sentido con la interpretación de estos cálculos. El objetivo de IPv6 no es el de asignar de una vez por todas una dirección IPv6 a un dispositivo (o a un ser humano). Una dirección IPv6 sólo tiene sentido y es útil cuando el dispositivo está conectado a la red. Además, si la ubicación del dispositivo en la red cambia, la dirección también debe ser modificada para reflejar este desplazamiento.
Tras definir lo que se espera de una dirección en Internet, el presente capítulo examina los diferentes tipos de direcciones. Se presenta con detalle el plan de direccionamiento agregado que fue seleccionado para construir las redes de evaluación y de producción. También se describe la forma de calcular los identificadores de interfaz utilizados por varios tipos de direcciones (véase también Infraestructura para la transmisión).
¿Qué es una dirección?
Hace mucho tiempo que se comprende la distinción entre las nociones de directorios, nombres, direcciones y rutas. Sin embargo, desde hace algunos años, el concepto de una dirección de red en el seno de Internet, ha evolucionado. En Internet, una dirección tiene dos funciones distintas: identificación y localización.
- La identificación se utiliza durante una conexión por cada una de las partes para reconocer a su interlocutor. Esto permite, entre otras cosas, asegurarse del origen de los paquetes recibidos.
Esta verificación se realiza en el pseudo-encabezado de TCP o en las asociaciones de seguridad de IPsec. La vida útil mínima de un identificador es la de una conexión TCP.
- La localización se utiliza para buscar un intermediario que sepa entregar los paquetes. La vida útil de la función de localización es suficientemente grande. De hecho, sólo varía si se hace el cambio de proveedor IP o por una reorganización del sitio.
En general, la localización está dividida en dos partes: localización global (que identifica a la red) y local, que distingue a las máquinas en una misma red. La localización está intrínsecamente vinculada a las funciones de enrutamiento IP.
En IPv4, identificación y localización son indistinguibles una sola entidad, la dirección IP, única globalmente en Internet. Esta construcción tiene un costo: cuando debe renumerarse un sitio, o cuando un móvil se desplaza, cambia su localización. Bajo el enfoque IPv4, la dirección IP cambia, y por lo tanto la identificación... Esto implica una pérdida, o en el mejor de los casos, una renegociación de las comunicaciones en curso.
Durante los estudios iniciales de IPv6, se propuso separar estas dos funciones para resolver de manera sencilla los problemas de renumeracion, movilidad, multi-dommiciliación (multi-homing)... Ello sigue siendo un tema de investigación, pues dicha propuesta no fue retenida; en IPv6 como en IPv4, la dirección se utiliza tanto para la identificación como para la localización. El esquema de direccionamiento elegido es una extensión de las reglas de direccionamiento jerárquico (CIDR) utilizadas en IPv4.
También existe un debate sobre si una dirección identifica a una máquina o a una interfaz de red. Esta distinción no es muy importante en el caso de una máquina sencilla que tiene sólo una interfaz, pero es relevante cuando el dispositivo tiene varias interfaces, o si es multi-domiciliado. Para tratar de simplificar las tablas de enrutamiento en el núcleo de la red, si un sitio está conectado a varios proveedores de acceso, tendrá tantos prefijos IPv6 como proveedores. A diferencia de IPv4, donde generalmente se asocia una sola dirección a una interfaz, en IPv6 una interfaz tiene varias direcciones.
Estructuración de direcciones y agregación
Uno de los principales problemas de IPv4 es el crecimiento descontrolado de las tablas de enrutamiento. Este fenómeno se deriva de una agregación inadecuada de direcciones en las tablas. Debería contarse con la capacidad de agregar conjuntos de redes identificadas por un único descriptor. CIDR aporta una mejora, pero ésta es insuficiente en la práctica: las direcciones IPv4 son demasiado cortas para permitir una estructuración adecuada; además, se debe asumir el costo de todas las direcciones ya asignadas.
Asignar una dirección a un dispositivo es un proceso complejo; debe haber un compromiso entre la facilidad de asignación y la facilidad de gestión. Idealmente, para minimizar el enrutamiento, la red debería tener una topología de árbol, lo cual ofrecería un direccionamiento jerárquico muy eficaz. En realidad, por razones económicas, técnicas, geográficas y de rendimiento, la red es mucho más compleja, visualizada como un grafo. Deben introducirse excepciones en las tablas de enrutamiento para reflejar esta topología. Con el fin de maximizar la eficacia en el direccionamiento, debe encontrarse en este grafo la representación arborescente que genera el menor número de excepciones posibles.
Ahora bien, aún si se encontrara una representación válida para hoy, ésta ya no necesariamente lo sería el día de mañana. Por ello, la definición del plan de direccionamiento debe ser lo más flexible posible con el fin de facilitar una evolución que es impredecible por naturaleza.
Esto es aún más importante ahora que la agregación para IPv4 ya no parece tan eficaz. La siguiente figura muestra la evolución de las tablas de enrutamiento en el núcleo de Internet, es decir, en las redes de operadores, donde no se especifica ninguna ruta por omisión.

En el año 2000, la progresión lineal de esta tabla parecía ser alterada por:
- La caída en el costo de los enlaces de larga distancia, que facilitó la multi-domiciliación (multi-homing) de los sitios para aumentar la fiabilidad (en caso de una falla del operador, el tráfico podrá transitar por otro) y el rendimiento (conectarse directamente con la red con la que el sitio tiene un tráfico importante),
- la falta de direcciones IPv4, que obliga a los operadores a asignar prefijos cada vez más largos.
Desde entonces, los operadores han enfatizado escrupulosamente la agregación para regresar a una progresión lineal de las tablas. Algunos estudios [BTC02] muestran que:
- La multi-domiciliación, es decir, la conexión de un sitio a varios operadores para dar fiabilidad al acceso, incrementa las tablas en un 20% a 30%,
- el balanceo de carga, es decir, reducir la agregación para anunciar a cada operador un subconjunto del prefijo, introduce un sobre costo de 20% a 25%,
- las reglas de agregación inadecuadas incurren en un sobre costo de 15% a 20%,
- la fragmentación del espacio de direccionamiento ligada a la gestión de prefijos antes del uso de CIDR y a la asignación secuencial de bloques de direcciones, contribuye en más 75% al tamaño de la tabla.
Para poder asegurar una buena agregación, hoy en día se conservan las reglas utilizadas por CIDR para IPv4, pero la gestión de las tablas de enrutamiento en el núcleo de la red se mejora debido a:
- Desde el principio, el plan de direccionamiento es jerárquico, eliminando los prefijos largos;
- los sitios multi-domiciliados tendrán tantas direcciones como proveedores de acceso, permitiendo garantizar una agregación,
- los mecanismos de renumeración automáticos permiten a los sitios cambiar de prefijo fácilmente cuando ello sea necesario.
Un plan de direccionamiento jerárquico parece ser el más adecuado en la actualidad, pero otras reglas de numeración podrían aparecer en el futuro, por ejemplo, basadas en las coordenadas geográficas de los dispositivos. Estas técnicas sólo se utilizan hoy en día en algunos laboratorios de investigación para redes ad hoc, pero el espacio de direccionamiento tiene la capacidad suficiente para tomar en cuenta a estos nuevos tipos de redes si algún día se generaliza su uso.
La elección de un plan de direccionamiento ha sido objeto de numerosos debates en el IETF. Ha resultado mucho mas difícil definir un plan, que el formato de paquete IPv6, el cual se presenta en el siguiente capítulo. Varios planes se han propuesto y abandonado. Algunos de estos planes de direccionamiento se comentan en el capítulo sobre la Historia de la estandarización de IPv6. El presente capítulo se limita a describir los diferentes planes de direccionamiento que se utilizan en la actualidad.
| |
Introducción | Table des matières | Planes de direccionamiento | |